Neuroevolutions
Published:
In the landscape of artificial intelligence, most breakthroughs in control and decision-making tasks have been driven by gradient-based methods, particularly Reinforcement Learning powered by deep neural networks trained through backpropagation. WHile these approaches are incredibly effective, they rely heavily on dense reward signals, differentiable environments, and delicate hyperparameter tuning, conditions that are not always guaranteed in real-world problems.
This project takes a radically different approach: Applying Genetic Algorithms to evolve neural networks that can solve complex RL environments without relying on gradients at all. This technique, known as Neuroevolution, replaces traditional learning with an evolutionary process inspired by natural selection, allowing agents to adapt and improve solely through mutation, crossover, and fitness evaluation.
Over the course of this exploration, I tackled three distinct and popular reinforcement learning tasks of increasing complexity:
- CartPole-v1: A classic control problem where the agent must balance a pole on a moving cart.
- LunarLander-v3: A moderately complex physics-based environment where the goal is to land a spacecraft softly on a platform.
- BipedalWalker-v3: A challenging continuous control task requiring a two-legged robot to learn how to walk across rugged terrain.
For each of these environments, I implemented a modular genetic algorithm from scratch, encoding neural networks as genomes and evolving them over generations of gitness-based selection. I experimented with various selection mechanisms (such as tournament and rank-based), mutation operators, and architectural choices, observing how different strategies affected learning dynamics and convergence behavior.
This post provides a deep dive into the design of the algorithm, the neural models evolved, and the results obtained across the three tasks. It concludes with a comparative analysis of the environments and a reflection on the strengths and limitations of neuroevolution as a tool for solving reinforcement learning problems, even in the complete absence of gradient information.
What is Neuroevolution?
Neuroevolution is the application of the evolutionary algorithms for training of neural networks. Unlike traditional machine learning methods that use gradient descent to minimize loss functions, neuroevolution treats the neural network as a black-box policy whose parameters (weights and biases) are evolved through genetic principles like selection, mutation and crossover.
At it’s core, the idea is simple:
Initialization: Begin with a population of randomly initialized neural networks, each represented by a genome, typically a flat vector representing all weight parameters of the neural network.
Evaluation: Each genome is evaluated in an environment and assigned a fitness score based on the performance of the neural network with the genome weights.
Selection: The most successful individuals are then selected based on their fitness to act as parents for the next generation.
Replacement: A new population is formed and the cycle continues for many generations.
Through this process, populations of neural networks adapt to their environment over time, not by learning from data in the traditional sense, but by evolving through trial and error in the designated environment.
Why Neuroevolution?
There are several reasons why neuroevolution is an attractive alternative to gradient-based learning algorithms:
Gradient-Free Optimization: Neuroevolution doesn’t require the environment or the policy to be differentiable. This makes it ideal for environments with sparse, delayed or noisy rewards.
Exploration by Design: Evolutionary algorithms naturally encourage diverse solutions, often discovering creative strategies that gradient-based methods overlook due to local minima.
Robsustness: Neuroevolution can be more robust to noisy observations, chaotic dynamics, or discontinuous reward landscapes, where gradient descent might fail or diverge.
Parallelism: Fitness evaluations are embarrassingly parallel, each genome of the same generation can be tested independently, allowing massive scalability across compute nodes.
Despite these advantages, neuroevolution also comes with trade-offs. It is typically slower to converge, less sample efficient, and harder to scale to very high-dimensional networks unless specialized strategies are used (e.g. NEAT, CMA-ES, novelty search, …). However, for environments with a manageable input/output space and well-defined episodic structure, like those in this project, neuroevolution proves to be an elegant and effective learning paradigm.
Genetic Algorithm Design
At the core of this project is a Genetic Algorithm designed from scratch to evolve neural networks capable of solving diverse reinforcement learning tasks. Each agent in the population is encoded as a genome, a flattened NumPy vector representing all of the neural network’s weights and biases. The GA proceeds through the standard evolutionary steps: initialization, evaluation, selection, crossover and mutation. However, several design choices were adapted per environment to better handle the increasing complexity of the tasks and explore different approaches and strategies.
Genome Representation
Each genome corresponds to a fixed-size neural network architecture, with parameters packed into a flat vector:
genome_size = input_size * hidden1_size + hidden1_size + hidden1_size * hidden2_size + hidden2_size + hidden2_size * output_size + output_size
This structure includes all weights and biases across up to two hidden layers. The number of layers is fixed in the architecture per environment and the nodes can be modified through variables, allowing consistent evaluation and mutation operations throughout evolution.
Neural Network Architecture
The neural network structure varied by environment to reflect increasing task difficulty:
| Environment | Hidden Layers | Hidden Nodes | Output Activation |
|---|---|---|---|
| CartPole-v1 | 1 | 8 | tanh + threshold |
| LunarLander-v3 | 2 | 10 per layer | argmax (raw logits) |
| BipedalWalker-v3 | 2 | 24 per layer | tanh (continuous) |
All hidden layers use tanh activation, encouraging bounded, non-linear transformations. For output layers the choice was task-specific:
In CartPole, the final output was processed post-inference to produce binary actions. While tanh + threshold worked well, a binary step might be a more elegant and cleaner solution, a potential refinement for future iterations.
In LunarLander, discrete actions were selected via argmax, so the output layer produced raw values (no activation required).
In BipedalWalker, the tanh output directly controlled continuous joint torques.
Selection Strategies
Selection strategies evolved alongside the projects as the complexity of the projects increased.
For CartPole & LunarLander two parents were selected randomly and without substitution from the top 20% performers. This strategy, although simple, it’s very effective since it encourages elitism and maintains diversity.
For BipedalWalker I switched to tournament selection, a technic where 5 random genomes are compared against their and the best performer is selected to be a parent. This improved exploration of high-performing genomes while preserving competitive pressure among the rest. This transition was motivated by the need for more adaptative pressure in a higher-dimensional and more deceptive fitness landscape.
Crossover Operators
Different crossover schemes were applied based on environment complexity:
For CartPole & LunarLander I used Uniform Sampling where each genome is randomly inherited fo¡rom either parent. Simple, effective, and computationally cheap.
For BipedalWalker I wanted to give a twist and try a Masked Uniform Crossover. This approach generates two symmetric children via a binary mask, allowing more structured recombination of parental traits, helpful in high dimensional search spaces. Also a crossover rate was applied which controlled wether crossover was applied or if parents were copied directly.
Mutation Strategies
Mutation was the primary driver of exploration. The mutation approach matured through the project as the problems complexity increased.
For CartPole I induced direct noise scaled by a mutation rate:
mutation = np.random.randn(len(genome)) * mutation_rate
For LunarLander I wanted to clip the noise between -0.1 and 0.1 to try and achieve more stability to the mutation.
Finally in BipedalWalker a per-gene probabilistic mask was introduced, improving control over how frequently and strongly mutation occurs.
mask = np.random.random(self.genome_length) < mutation_rate
noise = np.random.normal(0, mutation_strength, self.genome_length)
return genome + mask * noise
Elitism
In all projects, 1-2 of the top performing individuals were directly carried over to the next generation. This ensured that good solutions were never lost due to stochastic genetic operations and allowed for steady performance improvements over time.
Population and Generations
Population size was held constant at 50 individuals per generation, while the number of generations was scaled to the task complexity.
| Environment | Population | Generations |
|---|---|---|
| CartPole-v1 | 50 | 1000 |
| LunarLander-v3 | 50 | 5000 |
| BipedalWalker-v3 | 50 | 10000 |
The amount of generations where above the observed minimum necessary generations for convergence. This choice allowed to see further behavioral changes once the fitness values converged and the genomes where considered a solution, particularly in BipedalWalker, where walking policies often require thousands of generations to evolve from scratch and an environment valid solution might not be considered valid to the human eye.
CartPole-v1: The Balancing Act
The CartPole-v1 environment is a classic reinforcement learning benchmark, where the agent must balance a pole on a moving cart by applying discrete left or right forces. Through conceptually simple, it serves as an excellent entry point for testing evolutionary strategies due to its short episodes, fast simulation time, and binary action space.
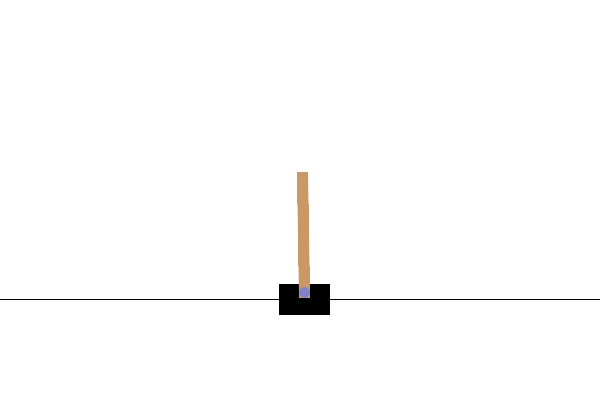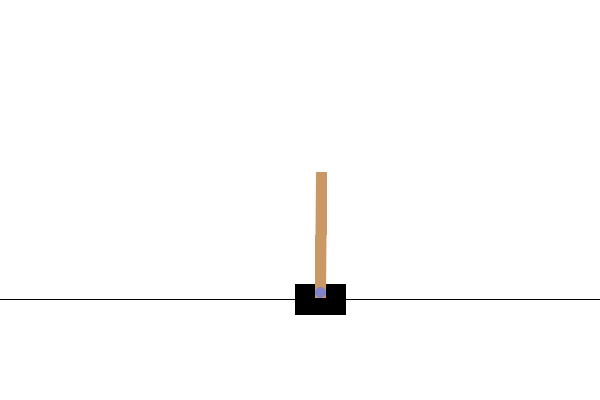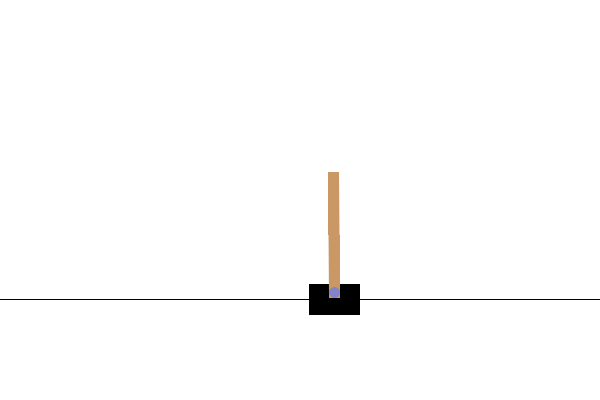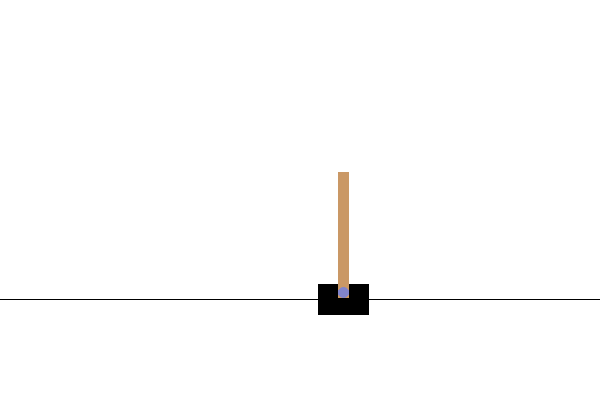
Figure 1: One of the top performing agents in the CartPole-v1 environment.
Proble Setup
- Observation Space: 4 continuous values: position, velocity, angle, angular velocity
- Action Space: Discrete (0 = Left, 1 = Right)
- Max Episode Length: 500 time steps
- Reward: +1 per time step if the pole stays upright
The task is solved when the agent consistently survives for 500 steps.
Neural Network design
For this task, I used a lightweight neural network:
- Input Layer: 4 neurons (one per observation)
- Hidden Layer: 1 layer with 8 tanh activated neurons
- Output Layer: 1 neuron with tanh activation, with threshold to produce binary action (left or right)

Figure 2: Neural Network Architecture for the CartPole neuroevolution.
Although a Binary Step activation might have been a more natural fit for binary classification, tanh worked well and offered symmetric output values around 0. Future improvements could explore this trad-off more systematically.
Evolutionary Configuration
| Component | Configuration |
|---|---|
| Population Size | 50 |
| Generations | 1000 |
| Selection | Random sampling from top 20% performers |
| Crossover | Pre-gene uniform sampling between two parents |
| Mutation | Gaussian noise scaled by mutation rate |
| Elitism | Top 2 genomes preserved |
The genome encoded all weights and biases in a single vector. Each generation involved evaluating all agents, ranking them by fitness (total reward), and producing the next generation through crossover and mutation.
Results
By generation 400, the top performers already balance the pole all the way to the 500 steps. Evolutionary pressure gradually converged all the population into a valid solution. The simplicity of the environment eased the algorithm into a rapid convergence although having a very small mutation rate.
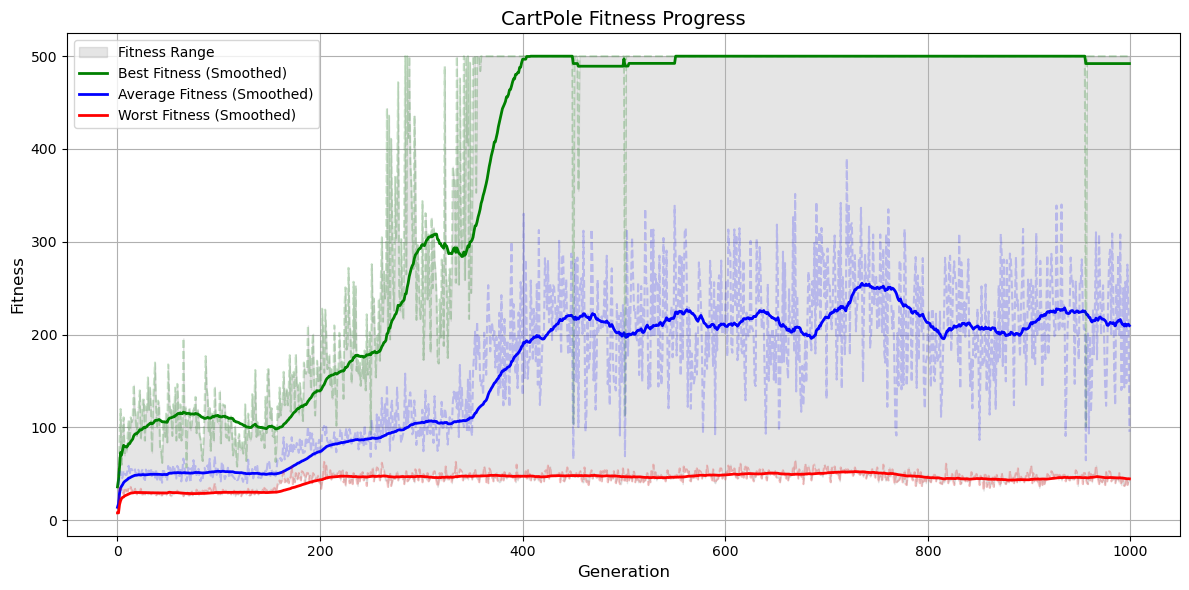
Figure 3: Fitness evolution for the CartPole neuroevolution.
LunarLander-v3: Mastering Controlled Descent
The LunarLander-v3 environment from OpenAI Gym introduces a significant leap in complexity compared to CartPole. Here, an agent must land a lunar module safely between two flags on rugged terrain, minimizing fuel usage while avoiding crashes or drifting off course. It’s a discrete-action environment with a continuous, noisy state space, making it an ideal testbed for mor sophisticated neuroevolution strategies.
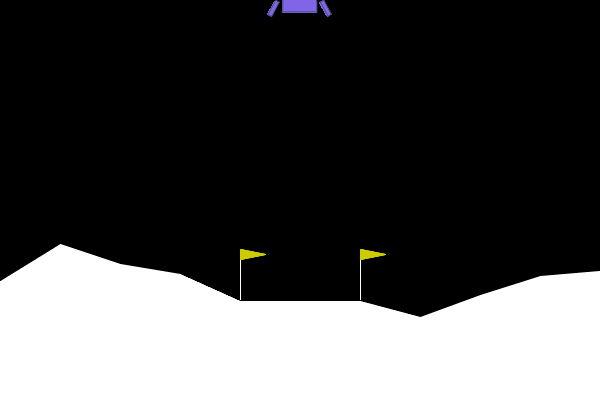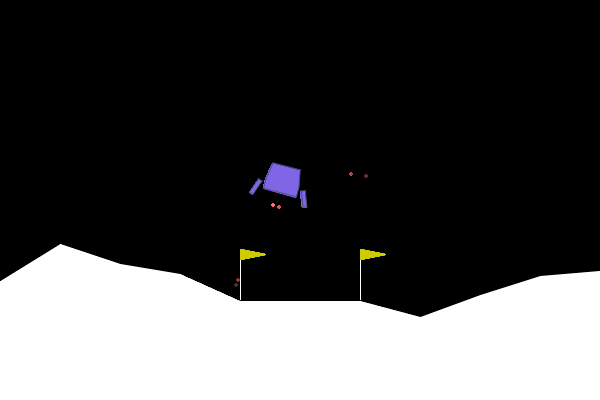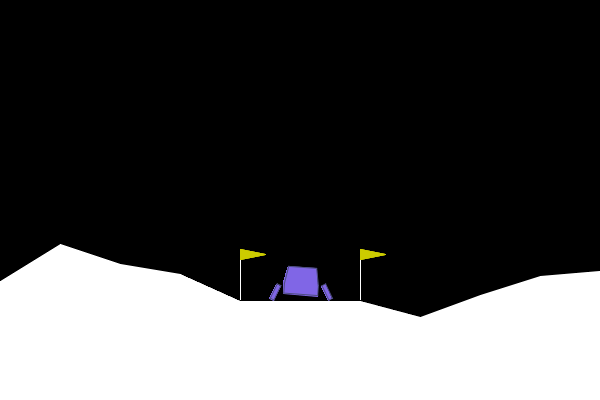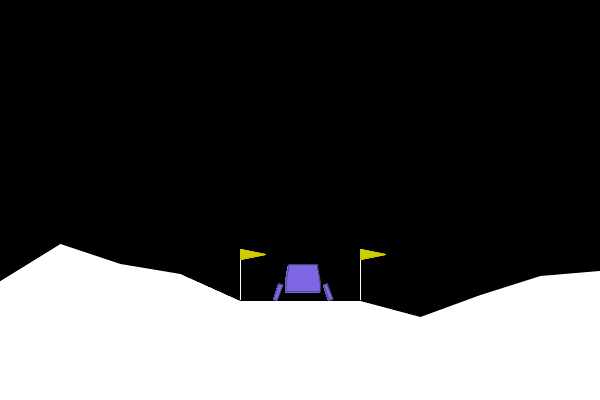
Figure 4: One of the top performing agents in the LunarLander-v3 environment.
Problem Setup
- Observation Space: 8 dimension continuous vector:
- Position (x, y)
- Velocity (x, y)
- Lander angle and angular velocity
- 2 Leg ground contact booleans
- Action Space: 4 discrete actions:
- Do nothing
- Fire main engine
- Fire left engine
- Fire right engine
- Reward Structure:
- Shaped reward for approaching the landing pad
- Penalty for crashing
- Bonus for successful landing
The sparse reward structure and sensitive control requirements male this a challenging environment for gradient-free optimization.
Neural Network Design:
- Input Layer: 8 neurons matching the observation vector.
- Hidden layers: 2 fully connected layers with 10 tanh activation nodes per layer.
- Output layer: 4 nodes with no activation. Final action for the environment is selected using argamax over the raw output.

Figure 5: Neural Network Architecture for the LunarLander neuroevolution.
The architecture was designed to allow deeper signal processing compared to CartPole. Using raw linear outputs in the final layer allowed cleaner action selection and avoided vanishing effects from output activations.
Evolutionary Configuration
| Component | Configuration |
|---|---|
| Population Size | 50 |
| Generations | 5000 |
| Selection | Top 20% sampling |
| Crossover | Pre-gene uniform crossover |
| Mutation | Gaussian noise with value clipping [-0.1, 0.1] |
| Elitism | Top 2 individuals retained |
Compared to CartPole, mutation clipping helped ensure the network didn’t suffer from destabilizing parameter explosions, while preserving diversity across the population.
Results
Early generations exhibited erratic flying and frequent crashes. With time, evolved agents began:
- Using the main thruster efficiently
- Orienting before descent
- Making soft landings with minimal horizontal drift
Before the first 500 generations the agent often landed out of the desired location. In further generations, the agent learned to orient it’s landing to the designated location, though in the late stages some would still overshoot or hover excessively, reflecting the ruggedness of the reward surface.
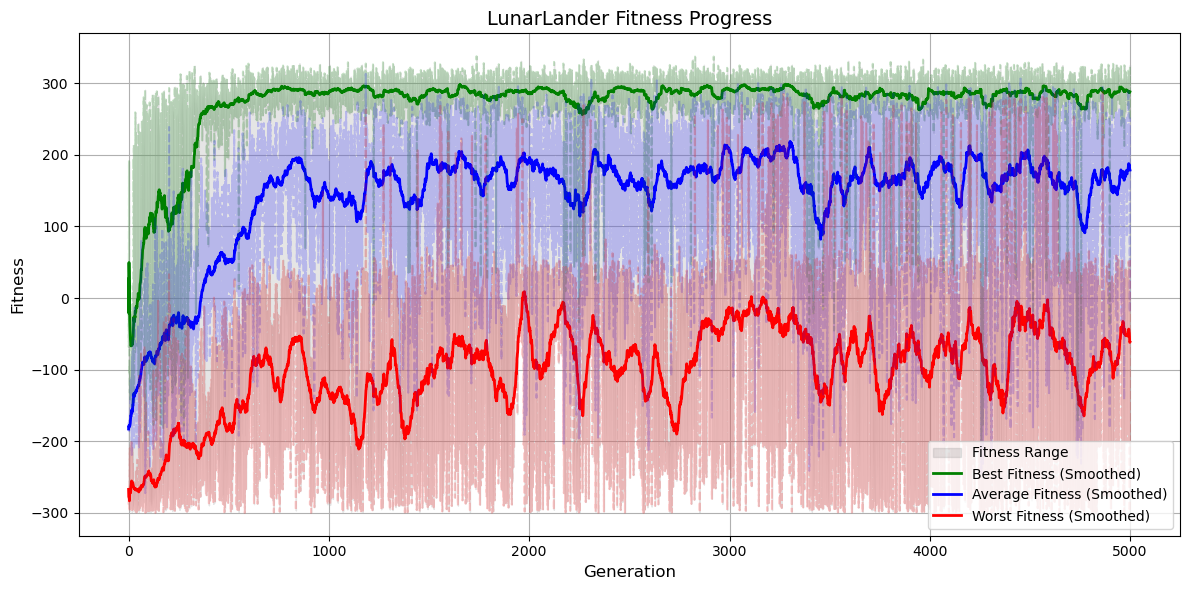
Figure 6: Fitness evolution for the LunarLander neuroevolution.
BipedalWalker-v3: Evolving Locomotion
The BipedalWalker-v3 environment simulates a two-legged robot that must learn to wal across an uneven terrain. It’s widely regarded as a benchmark for advanced control tasks due to its 24 dimensional observation space, 4 dimensional continuous action space and the sparse rewards and fragile dynamics.
Unlike previous environments, BipedalWalker demands a long-term coordination, balance, and non-trivial timing, making it a formidable test for neuroevolution’s scalability and adaptability.

Figure 7: One of the top performing agents in the BipedalWalker-v3 environment.
Problem setup
- Observation Space: 24 continuous variables describing joint angles, velocities, contact sensors and more.
- Action Space: 4 continuous outputs [-1, 1], each controlling a motor torque.
- Reward:
- Distance walked gives a positive reward
- Falling/crashing implies a large penalty
- Energy efficency and stability are implicitly rewarded
The goal is to walk as far as possible without falling, a difficult feat without backpropagation or engineered priors.
Neural Network Design
For this task, I scaled up the network capacity:
- Input Layer: 24 neurons
- Hidden Layers: 2 fully connected layers with 32 tanh activate neurons per layer.
- Output Layer: 4 tanh activated neurons directly mapped to motor torques.

Figure 8: Neural Network Architecture for the BipedalWalker neuroevolution.
This wide architecture was essential to process the high dimensional sensory input and produce finely tuned motor outputs required for balance and progression.
Evolutionary Configuration
| Component | Configuration |
|---|---|
| Population Size | 50 |
| Generations | 10000 |
| Selection | Tournament selection (size = 5) |
| Crossover | Masked uniform crossover with crossover probability |
| Mutation | Per-gene probabilistic mutation + Gausian noise |
| Elitism | Top 2 individuals retained across generations |
The move to tournament selection provided stronger selective pressure in such a rugged fitness landscape, while still preserving some diversity. Mutation on the other hand was carefully controlled using a masking approach. This allowed sparse but strong exploratory steps, crucial for escaping local optima in this environment.
Results
Training took significantly longer than previous tasks. In the early generations agents failed, spasmed, or collapsed immediately. But eventually the agents learned to get to the end point, however it couldn’t be considered a bipedal walker since the agent was dragging one leg or finding ways to hack the reward system.
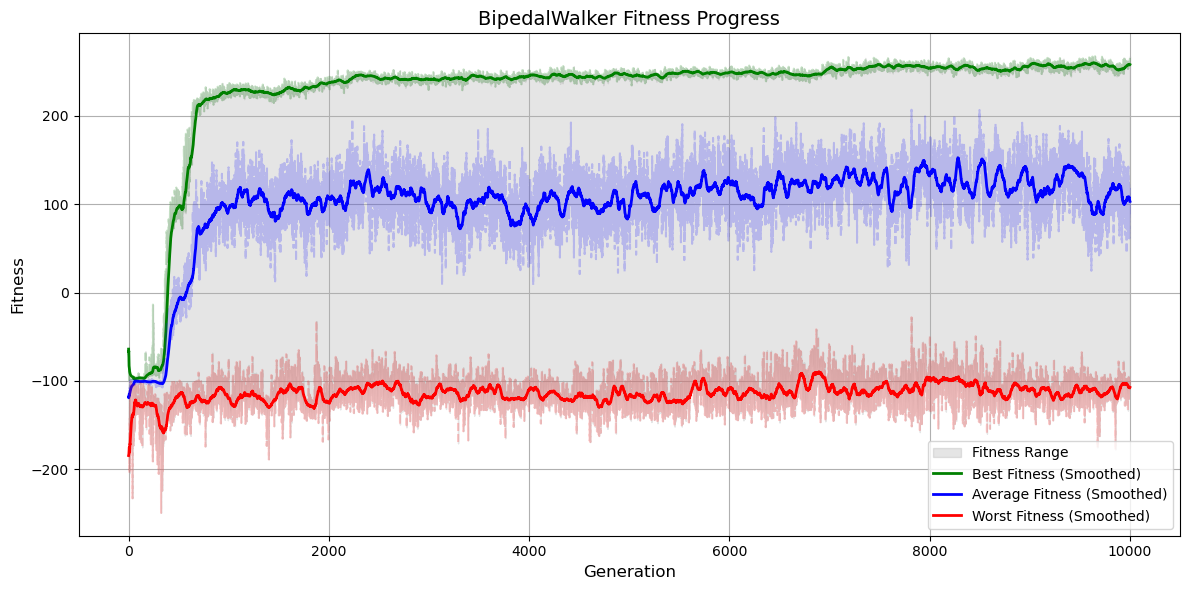
Figure 9: Fitness evolution for the BipedalWalker neuroevolution.
Reflections on Neuroevolution
Working through these three progressively complex reinforcement learning environments using genetic algorithms has provided me with deep insight into both the power and the limitations of neuroevolutionary strategies.
What I Learned Technically
At its core, this project revealed how genetic algorithms can effectively search high-dimensional, non.differentiable spaces to evolve intelligent behavior. While modern RL typically relies on gradient-based optimizations, here I bypassed backpropagation entirely. By encoding neural networks weights as flat genomes and optimizing solely via fitness-based selection, I could evolve agents that learned to balance, land and even walk purely through stochastic search.
This approach required me to deeply understand network architecture design, mutation dynamics, and selection pressure. For example CartPole needed minimal complexity and learned quickly with a shallow network. LunarLander required fine-grained mutation strategies and longer runs to evolve precise thruster control. Finally BipedalWalker with its high-dimensional action space and deceptive reward landscape, exposed the brittleness of naive strategies and pushed me to explore and adopt new strategies ending with tournament selection and a more robust crossover and mutation schemes.
Each environment taught me to adapt the algorithm, not just in terms of parameters, but in strategy. I gained first-hand experience in designing evolution processes that could scale with complexity.
Conceptual Insights
One of the most striking outcomes was the mergence of intelligent behavior from entirely random initializations, without any direct teaching signal or gradients. Watching agents evolve walking gaits, stabilize landings, or balance poles showed the power of evolution to generate behavior, not just optimize numbers.
It also highlighted why neuroevolution is so well-suited to sparse and delayed reward problems. Unlike temporal difference methods that struggle when rewards are infrequent or noisy, genetic algorithms treated the policy as a black box and optimize for outcome directly. This makes them resilient in environments where exploration is hard or gradients are misleading.
Another key realization was how genotype-to-phenotype mapping shapes evolvability. Small genome perturbations often lead to large behavioral changes, particularly in deeper/wider networks. Balancing mutation strength and structural stability became a key design decision.
Engineering and Practical Lessons
This project wasn’t engineering challenges free. I would like to highlight the three main challenges I found along the way:
Reward Hacking appeared in early LunarLander runs, where agents learned to hover just above the landing pad instead of touching down. Also in BipedalWalker, agents got from the starting point to the finish line by dragging the real leg and skipping with the front leg.
Fitness plateaus emerged frequently in both LunarLander and BipedalWalker, thanks to reward hacking. This required a more aggressive exploration through mutation and crossover.
Evaluation noise and stochasticity in Gym environments made fitness comparisons unstable at times, pushing me to averaging over multiple rollouts for robust evaluation.

Figure 10: An example of a BipedalWalker agent Reward Hacking it's way to a "valid solution".
On the other hand the simplicity of the evolutionary loop allowed for rapid iteration. No gradients meant no need for backrpopagation code or differentiable environments. I could swap activation functions, mutate architectures, or tyr different selection schemes with minimal overhead.
And perhaps the most rewarding was the visual feedback. Being able to render and watch agents evolve over generations gave me a uniquely intuitive understanding of progress. It also helped debug behavior that weren’t reflected in scalar rewards, like reward hacking.
Connection to Research and Beyond
This exploration has equipped me with practical tools and conceptual grounding that align closely with my research interests, particularly in optimization, search-based learning, and alternative learning paradigms.
In preparation for my computer engineering thesis on Quantum Genetic Algorithms, this project served as a perfect introduction to evolutionary search principles, as well as the challenges of encoding, mutation, and convergence. It also offered a taste of the potential in hybrid learning systems, where differentiable modules can be combined with evolutionary controllers.
More broadly, it reinforced the idea that there is no one-size-fits-all in machine learning. Neuroevolution is not always, by far, the most efficient method, but it’s robust, interpretable, and surprisingly effective in complex, rugged fitness landscapes.
Source Code
You can explore the full codebases for each task in the following GitHub repositories: