Mastering Minimax: Building a Perfect Tic Tac Toe AI
Published:
Why Minimax?
Imagine sitting down for a game of Tic Tac Toe. You’re playing seriously, and so is your opponent. Every move you make is carefully chosen, and every move they make is intended to block or defeat you. Neither of you makes mistakes. In this kind of situation, how do you decide your next move?
This is the core motivation behind the Minimax algorithm.
Minimax comes from game theory, the study of strategic decision-making. It is designed for two-player, turn-based, zero-sum games. Zero-sum means that one player’s gain is always the other player’s loss. In Tic Tac Toe, if you win, your opponent loses, if you lose, they win, if you draw, nobody gains.
The brilliance of minimax is that it provides a way to reason about the future of the game, by assuming both players play optimally. If you use minimax correctly, you will always secure the best possible outcome: either a win or, in the worst case, a draw.
The Core Idea of Minimax
The idea of minimax is deceptively simple:
- When it’s your turn (the maximizing player), you choose the move that gives you the best possible outcome.
- When it’s your opponent’s turn (the minimizing player), they will try to reduce your chances, so you assume they always pick the worst possible outcome for you.
To reason about this, we construct a game tree. Each node of the tree represents a board state, and each edge represents a move. At the very bottom, the leaves are terminal positions where the game ends (win, lose, or draw).
Once we have this tree, we can evaluate the outcomes numerically:
- Win =
+1 - Draw =
0 - Loss =
-1
By propagating these values back up the tree, we can decide the best move from the current position. Maximizing nodes pick the highest value available, minimizing nodes pick the lowest.
This back-and-forth alternation of maximizing and minimizing ensures that the algorithm accounts for the best moves you can make and the best counter-moves your opponent can make.
Minimax in Action: Tic Tac Toe
Consider a Tic Tac Toe board where it’s X’s turn.
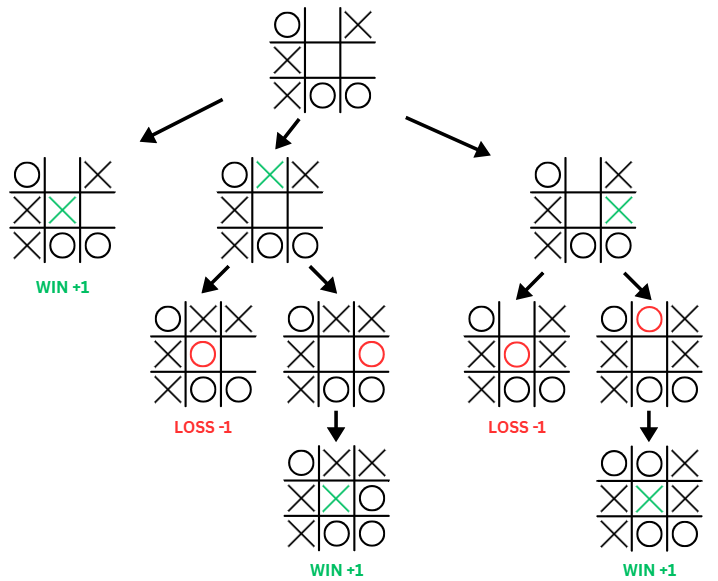
X can place a symbol in several open squares. For each of those moves, O will get a chance to respond. Some responses may lead to X eventually winning, others to a draw, and others to O winning.
By expanding the tree fully until all games are finished, we can label each branch with its eventual outcome. Then, minimax tells X which move to pick: the one that maximizes the minimum guaranteed result.
This is what makes minimax so powerful: it is not just about grabbing the most tempting move, but about anticipating what your opponent will do afterwards. Even in such a simple game as Tic Tac Toe, this recursive reasoning is enough to make the AI unbeatable.
The Problem: Complexity
Tic Tac Toe is small. The total number of possible games is only around 255,168. For modern computers, searching the entire tree is trivial.
But what if we want to apply minimax to more complex games like Chess or Go? The game tree explodes in size. In Chess, there are often over 30 legal moves per position, and games can last for dozens of moves. Searching every possibility becomes impossible.
So how can minimax scale?
Alpha-Beta Pruning
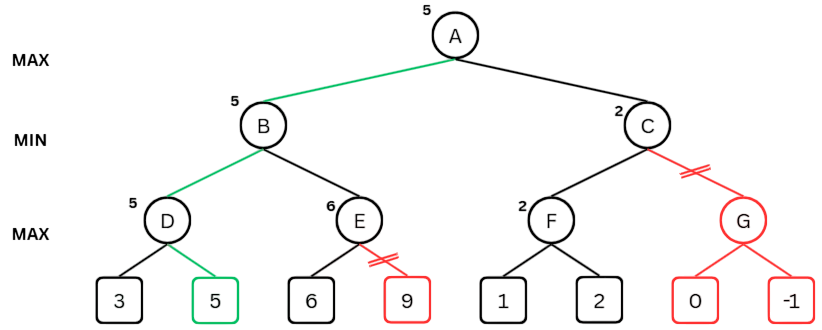
The answer is alpha-beta pruning, an optimization that reduces the number of nodes we need to evaluate in the game tree.
The idea is to keep track of two values:
- alpha: the best score the maximizer (us) can guarantee so far.
- beta: the best score the minimizer (opponent) can guarantee so far.
As we explore the tree, if we ever reach a point where the minimizer’s guaranteed outcome is worse than something the maximizer already has (or vice versa), we can stop. That branch will never influence the final decision.
In other words, alpha-beta pruning allows us to skip entire subtrees without changing the result. For Tic Tac Toe, this is just an efficiency boost. For larger games like Chess, it’s absolutely essential.
Code
Here is a compact version of minimax with alpha-beta pruning:
def minimax(board, is_maximizing, alpha, beta):
if board.is_terminal():
return board.score()
if is_maximizing:
value = -∞
for move in board.available_moves():
board.make_move(move, "X")
value = max(value, minimax(board, False, alpha, beta))
board.undo_move(move)
alpha = max(alpha, value)
if alpha >= beta:
break # prune
return value
else:
value = +∞
for move in board.available_moves():
board.make_move(move, "O")
value = min(value, minimax(board, True, alpha, beta))
board.undo_move(move)
beta = min(beta, value)
if beta <= alpha:
break # prune
return value
This simple recursive function is enough to make Tic Tac Toe unlosable. The AI evaluates all possible futures, prunes away impossible branches, and always plays perfectly.
From Theory to Tic Tac Toe
In Tic Tac Toe, the full minimax algorithm is feasible without heuristics or approximations. This means the AI will:
Always capitalize on mistakes.
Never lose to a weaker opponent.
Force a draw against perfect play.
This is exactly what we built in our project. By embedding minimax with alpha-beta pruning inside a simple Tic Tac Toe engine, we created a perfect AI opponent.
What’s interesting is not just that the AI never loses, but that it demonstrates the principle of optimal play. Even a tiny game like Tic Tac Toe becomes an arena for deep reasoning once you apply minimax.
Wrapping Up
Minimax is one of those algorithms that is easy to understand yet incredibly powerful. It introduces fundamental ideas in both AI and game theory:
Reasoning about the worst case rather than the best.
Modeling opponents as rational adversaries.
Optimizing search with pruning.
These ideas scale far beyond Tic Tac Toe. With heuristics and optimizations, minimax forms the backbone of many competitive game AIs, from Chess engines to modern reinforcement learning systems.
If you want to see the theory in action, try out the project:
Leave a Comment